- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Как провести стресс-тестирование вашей системы Linux
- Создаем циклы своими руками
- Специализированные инструменты для добавления нагрузки
- 6 приложений для анализа жесткого диска в Linux
- Командная строка
- Baobab
- KDirStat и GdMap
- Filelight
- Philesight
- xdiskusage
- База знаний wiki
- Содержание
- Проверка состояния жестких дисков в Linux
- Задача:
- Решение:
- Linux: проверка скорости чтения-записи HDD
- tune2fs
- hdparm
- seeker
- iozone
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как провести стресс-тестирование вашей системы Linux
4 минуты чтения
Повышение нагрузки на серверы Linux может быть хорошей идеей, если вы хотите увидеть, насколько хорошо они работают, когда они загружены. В этой статье мы рассмотрим некоторые инструменты, которые помогут вам нагрузить сервер и оценить результаты.
Для чего вам необходимо подвергать свою систему Linux нагрузке? Потому что иногда вам может потребоваться узнать, как система будет вести себя, когда она находится под большим давлением из-за большого количества запущенных процессов, интенсивного сетевого трафика, чрезмерного использования памяти и т. д. Этот вид тестирования позволяет убедиться, что система готова к использованию.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Если вам нужно спрогнозировать, сколько времени потребуется приложениям для ответа и какие процессы могут выйти из строя или работать медленно под большой нагрузкой, проведение стресс-тестирования заранее является очень хорошей идеей.
К счастью для тех, кому нужно знать, как система Linux отреагирует на нагрузку, есть несколько полезных методов, которые вы можете использовать, и есть инструменты, которые вы можете использовать, чтобы упростить этот процесс. В этой статье мы рассмотрим несколько вариантов.
Создаем циклы своими руками
Данный первый метод предполагает запуск некоторых циклов в командной строке и наблюдение за тем, как они влияют на систему. Этот метод нагружает ЦП, значительно увеличивая нагрузку. Результаты можно легко увидеть с помощью команды uptime или аналогичных команд.
В приведенной ниже примере мы начинаем четыре бесконечных цикла. Вы можете увеличить количество циклов, добавляя цифры или используя выражение bash , например <1..6>вместо «1 2 3 4».
В примере выше, команда, запускает четыре бесконечных цикла в фоновом режиме.
В этом случае были запущены задания 1-4. Отображаются как номера заданий, так и идентификаторы процессов.
Чтобы увидеть влияние на средние значения нагрузки, используйте команду, подобную показанной ниже. В этом случае команда uptime запускается каждые 30 секунд:
Если вы собираетесь периодически запускать подобные тесты, вы можете поместить команду цикла в скрипт:
В выходных данных вы можете увидеть, как средние значения нагрузки увеличиваются, а затем снова начинают снижаться после завершения циклов.

Поскольку показанные нагрузки представляют собой средние значения за 1, 5 и 15 минут, потребуется некоторое время, чтобы значения вернулись к нормальным для системы значениям.
Чтобы остановить циклы, выполните команду kill , подобную приведенной ниже — при условии, что номера заданий равны 1-4, как было показано ранее в этой статье. Если вы не уверены, используйте команду jobs , чтобы проверить ID.
Специализированные инструменты для добавления нагрузки
Другой способ создать системный стресс — это использовать инструмент, специально созданный для того, чтобы нагружать систему за вас. Один из них называется stress и может воздействовать на систему разными способами. Стресс-инструмент — это генератор рабочей нагрузки, который обеспечивает стресс-тесты ЦП, памяти и I/O.
С параметром —cpu команда stress использует функцию извлечения квадратного корня, чтобы заставить ЦП усердно работать. Чем больше указано количество ЦП, тем быстрее будет нарастать нагрузка.
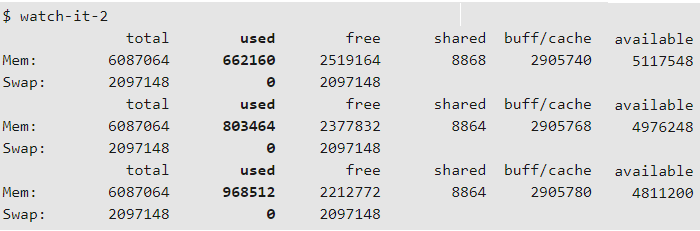
Второй сценарий watch-it (watch-it-2) может использоваться для оценки влияния на использование системной памяти. Обратите внимание, что он использует команду free , чтобы увидеть эффект стресса.
Начало и наблюдение за стрессом:
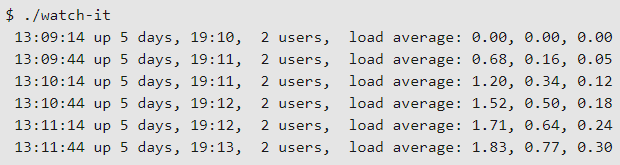
Чем больше ЦП указано в командной строке, тем быстрее будет нарастать нагрузка.
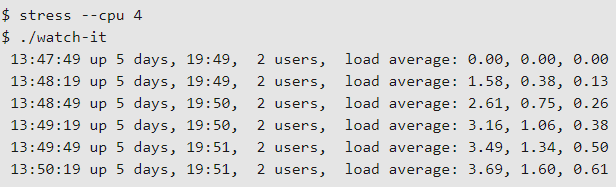
Команда stress также может вызвать нагрузку на систему, добавив I/O и загрузку памяти с помощью параметров —io (input/output) и —vm (memory).
В следующем примере выполняется команда для добавления нагрузки на память, а затем запускается сценарий watch-it-2 :
Другой вариант для стресса — использовать параметр —io , чтобы добавить в систему действия по вводу/выводу. В этом случае вы должны использовать такую команду:
После чего вы можете наблюдать за стрессовым I/O с помощью iotop . Обратите внимание, что iotop требует привилегий root .
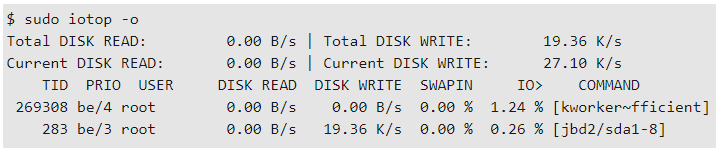
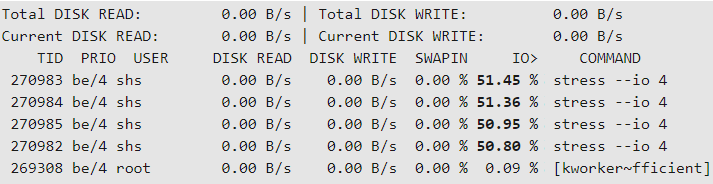
stress — это лишь один из множества инструментов для добавления нагрузки в систему.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
6 приложений для анализа жесткого диска в Linux
Командная строка
Если вы истинный линуксоид, самый легкий и быстрый способ – использовать команду «df» в командной строке. Просто напечатать:
в терминале, и он покажет вам загрузку жесткого диска в процентах

Как видно из представленного выше скриншота, способ может служить лишь в качестве быстрого просмотра доступного места на диске и определенно не является самым удобным для проведения анализа жесткого диска.
Baobab
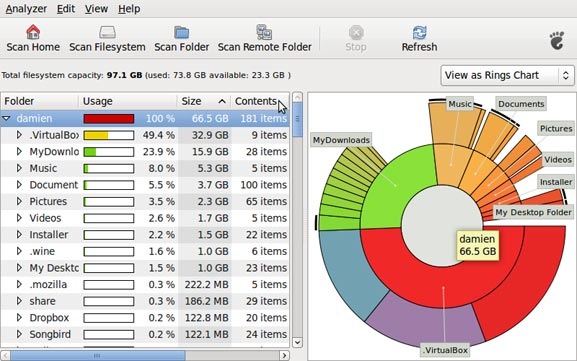
Большинство линукс-дистрибутивов с Gnome(в частности Убунту), используют Baobab в качестве дефолтного приложения для просмотра диска.Это замечательное приложение, способное до последней папки разделить и проанализировать структуру хранения данных на жестком диске. Просто укажите папки необходимые для сканирования, и в результате получите круговую диаграмму, отражающую количество занимаемого места каждым файлом.
KDirStat и GdMap
Если вы использовали WinDirStat в Windows, то согласитесь, что это очень удобное приложение, позволяющее анализировать и оптимизировать ваше дисковое пространство. Однако мало людей знают, что WinDirStat это на самом деле клон KDirStat. KDirStat обладает той же функциональностью что и WinDirStat (или может быть наоборот), за исключением того, что он предназначен для использования в Linux. Несмотря на то, что KDirStat разрабатывался для KDE, он также совместим с любым оконным менеджером X11.
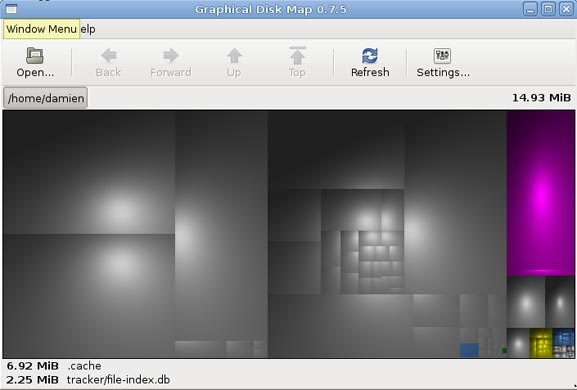
KDirStat отображает ваши папки/файлы в виде прямоугольников. Чем больше размер файла, тем больше прямоугольник. Это позволяет вам быстро просмотреть файловую систему, и легко определить какая папка/файл занимают много места на жестком диске.

Gd Map это эквивалент KDirStat для Gnome, кроме того что он не отображает древовидную структуру папок, и не позволяет очищать жесткий диск.
Filelight
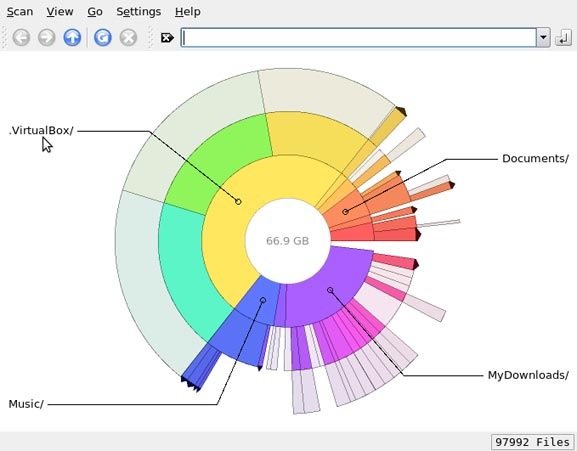
Подобно Baobab, Filelight, создает интерактивную карту концентрических, сегментированных колец, помогающих визуализировать использование диска на вашем компьютере.Вы легко можете приблизить нужные папки, путем клика на соответствующем сегменте колец.
Philesight
Philesight это реализация Filelight в качестве веб-приложения, может быть запущена на удаленном сервере, не имеющим графического интерфейса. Philesight использует командную строку для генерации PNG-файлов в браузере и включает CGI-скрипты для навигации по файловой системе. Одна из ее особенностей, красочная радуга концентрических колец, что делает ее весьма приятной на вид.

xdiskusage
xdiskusage маленькая программка, отображающая файловую систему иерархически, слева направо, прямоугольными фигурами, с размерами, соответствующими размеру файлов. Если вы сканируете домашнюю папку, слева будет находится прямоугольник, отображающий полностью папку home, а справа все файлы, находящиеся внутри нее.
Вы легко можете приближать/удалять, нужные папки, по двойному щелчку на соответствующем прямоугольнике.
Источник
База знаний wiki
Продукты
Статьи
Содержание
Проверка состояния жестких дисков в Linux
Слова для поиска: проверка дисков, hdparm, badblocks, smart, smartctl, iostat, mdstat
Задача:
Проверить состояние жестких дисков на выделенном сервере, наличие сбойных блоков на HDD, анализ S.M.A.R.T
Решение:
В этой статье будут рассмотрены способы проверки и диагностики HDD в Linux. Полученная информация поможет проанализировать состояние жестких дисков, и, если это необходимо, заменить носитель до того, как он вышел из строя неожиданно и в самый не подходящий для этого момент.
Задуматься о состоянии HDD следует по некоторым признакам поведения системы в целом: резко выросла общая нагрузка на дисковую подсистему, упала скорость чтения/записи, другие проблемы косвенно указывающие что с HDD что-то не то.
Ниже я приведу основные команды, выполнять их необходимо из-под учётной записи root
Чтобы получить список подключенных HDD в систему, выполнить:
Мы получим листинг всех подключенных накопителей, их размер и имена устройств в системе.
Для того, чтобы посмотреть какие устройства и куда смонтированы, выполнить:
Узнать сколько на каждом из смонтированном носителе занято пространства, выполнить:
Если мы используем софтовых RAID, его состояние мы можем проверить следующей командой:
Если всё в порядке, то мы увидим что-то подобное:
Из вывода видно состояние raid (active), название устройства raid (md0) и какие устройства в него включены (sdb1[0] sdc1[1]), какой именно raid собран (raid1), в нём два диска и они оба работают в raid ([2/2] [UU])
Смотрим скорость чтения с накопителя
Где /dev/sdX — имя устройства которое необходимо проверить.
Полезной программой для анализа нагрузки на диски является iostat, входящей в пакет sysstat Ставим:
Теперь смотрим вывод iostat по всем дискам в системе:
С интервалом 10 секунд:
Или по определённому накопителю:
Полученные данные покажут нам нагрузку на устройства хранения, статистику по вводу/выводу, процент утилизации накопителя.
Переходим непосредственно к проверке накопителей. Проверка на наличие сбойных блоков осуществляется при помощи программы badblocks. Для проверки жесткого диска на бэдблоки, выполнить:
Где /dev/sdX — имя устройства которое необходимо проверить. Если программа обнаружит наличие сбойных блоков, она выведет их количество на консоль. Выполнение данной операции может занять продолжительное время (до нескольких часов) и желательно её выполнение на размонтированной файловой системе, либо в режиме read-only.
Для того, чтобы записать сбойные блоки, выполняем:
Где /tmp/badblock — файл куда программа запишет номера сбойных блоков.
Теперь при помощи программы e2fsck мы можем пометить сбойные блоки и они будут в дальнейшем игнорироваться системой. ВНИМАНИЕ! Данная операция должна проводиться на размонтированной файловой системе, либо в режиме read-only! Проверенное устройство и устройство на накотором будут помечаться сбойные блоки должно быть одно и тоже!
Если были обнаружены сбойные блоки на диске, есть тенденция появления новых бэдблоков, необходимо задуматься о скорейшем копировании данных и замене данного носителя. Приведённые выше команды помогут выявить сбойные блоки и пометить их как таковые, но не спасут «сыпящийся» диск.
Также в своём инструментарии полезно использовать данные полученные из S.M.A.R.T. дисков.
Ставим пакет smartmontools
Получаем данные S.M.A.R.T. жесткого диска:
Где /dev/sdX — имя устройства которое необходимо проверить.
Вы получите вывод атрибутов S.M.A.R.T., значение каждого из которых хорошо описаны в Википедии
Для сохранности данных настоятельно рекомендуем делать backup (резервное копирование). Это поможет в кратчайшие сроки восстановить необходимые данные и настройки в форс-мажорных обстоятельствах.
Источник
Linux: проверка скорости чтения-записи HDD
На этом диске будут проводится тесты, описанные ниже:
Western Digital Caviar Green 500GB 64МB WD5000AZRX 3.5
О том, как получить подробные данные о вашем жестком диске — можно прочитать в статье Linux: получение информации о hardware — HDD.
tune2fs
Более подробную информацию об используемой файловой системе посмотреть можно с помощью tune2fs :
Конечно же, перед выполнением тестов убедитесь, что не запущены никакие задачи, создающие нагрузку на дисковую систему.
Самый простой способ проверки скорости чтения/записи на жесткий диск ( hard disk input/output value ):
Лучше выполнять его хотя бы 1-2 минуты. Почему — пояснение в следующих примерах:
424 МБ/с — по сравнению с 113 MB/s в предыдущем примере — почему такая разница?
dd вывел результат кеширования в буфер оперативной памяти, а не непосредственно на диск.
Укажем выполнить не 100 операций, а 1000 — что бы система успела выполнить синхронизацию RAM и HDD, после чего dd покажет нам результаты:
113 MB/s — тоже более реальный результат для это жесткого диска.
Другой способ — прямо указать dd дождаться окончания синхронизации данных (т.е. после фактического завершения операций записи/чтения данных на диск):
Теперь рассмотрим некоторые утилиты.
hdparm
Начнём с программы hdparm :
Ключ -t ( Timing buffered disk) отображает скорость чтения с диска напрямую из буфера кеша, и является показателем того, как быстро жесткий диск может поддерживать последовательное чтение данных под Linux, без задержек, вызванных работой файловой системы.
Ключ -T (Timing cached reads) показывает скорость чтения напрямую из буфера кеша Linux без учёта доступа к диску. Этот показатель главным образом отображает работу процессора, кэша и оперативной памяти тестируемой системы.
seeker
Одним из очень важных параметров скорости работы жесткого диска является «seek time» — время поиска. Это время, которое требуется жестком диску, что бы считывающая головка достигла сектора, содержащего необходимые данные. Что бы проверить этот параметр — воспользуемся утилитой seeker :
К сожалению, что бы её запустить под Debian / Ubuntu придётся немного повозиться.
Для начала, качаем .rpm пакет с сайта:
Например, вполне работоспособным (на Ubuntu 12.04 x64) оказался пакет seeker-3.0-2.el6.x86_64.rpm для CentOS 5.
На следующей странцие http://pkgs.org/centos-5-rhel-5/epel-x86_64/seeker-3.0-2.el5.x86_64.rpm/download/ выбираем:
Download packages from the official mirror:
binary package, source package
binary — и сохраняем пакет .rpm на диск.
Далее, потребуется создать пакет .deb . Для этого можно воспользоваться утилитой alien . Как ей пользоваться — описано в статье Установка Java 7 на Ubuntu 12.10.
iozone
Следующая утилита — iozone , которая фактически умеет выполнять все тесты, описанные выше. В Ubuntu 12.04 она требует установки, поэтому выполняем:
Теперь запустим и рассмотрим результаты:
(тут показана лишь малая часть всего вывода)
Ключ -a запускает iozone в автоматическом режиме, в котором утилита будет использовать для тестирования block size от 4k до 16384k (16M), и размер файлов от 64k до 524288k (512M).
Все результаты скорости указаны в KB/Sec.
Первая колонка — KB отображает размер файла.
Вторая колонка — reclen — отображает используемый размер блока (block size).
Третья колнка — write — отображает время, затраченное на создание/запись нового файла. Это всегда более сложная задача для диска и файловой системы, так как связана с назначением inode , созданием новой записи в журнале событий (для Journaled File System ) и т.п.
Четвёртая колонка — rewrite — указывается скорость перезаписи уже существующего файла.
Пятая колонка — read — скорость чтения существующего файла.
Шестая колонка — reread — скорость чтения файла, который уже был прочитан ( reread file ).
Седьмая колонка — random read — показывает скорость доступа к случайной части (!) файла.
В целом, этих данных хватит для получения необходимых данных о быстродействии жесткого диска. Более подробные данные можно еполучить на сайте>>> разработчкиа.
Сохранить результаты можно с ключём -b (файл должен быть совсемстим с форматом эл. таблиц):
Есть ещё много утилит, однако на этом хочется закончить.
Основная часть этой статьи является вольным переводом (с некоторыми попавками в описаниях) статьи Linux File System Read Write Performance Test.
Источник